출처: https://kyumdoctor.co.kr/18
nvidia-docker GPU 할당하여 사용 하는 방법 3가지
nvidia-docker 사용법
이전 포스팅에서 docker 설치 및 컨테이너 실행 옵션에 대해서 알아보았는데요. 오늘은 이어서 nvidia-docker에 대해서 적어보고자 합니다. nvidia-docker GPU 할당하여 사용 하는 방법은 굉장이 간단한데요.
docker와 사용방법은 같은데요. 일반 docker와는 달리 nvidia driver 및 toolkit들을 사용하여 GPU를 사용할 수 있게 해주는 nvidia-docker는 설치 방법은 docker설치와 별반 다를게 없습니다.
혹시 이전 Docker 설치 방법 및 실행 옵션에 대해 궁금하시다면 아래 포스팅을 참고 해주세요.
Docker 설치 및 컨테이너 실행 옵션 사용방법
Docker 설치 및 컨테이너 실행 옵션 사용방법 Docker? nvidia-docker2? 이번 포스팅에서는 Docker에 대해 알아보려고 합니다. 사실 이미 오래전부터 사용되었던 Docker이지만 모르는 분들을 위한 글이기
kyumdoctor.co.kr
nvidia-docker 설치 방법
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listgpgkey 입력 및 stable 저장소 추가 후
# apt-get update
# apt-get install nvidia-docker2 -y
# systemctl restart docker위와 같이 repository update 및 nvidia-docker2 를 설치 후 docker restart 후 간단하게 설치가 완료 됬습니다.
이제 NVIDIA-GPU를 할당하여 사용하는 방법 3가지에 대해서 알아보도록 하겠습니다.
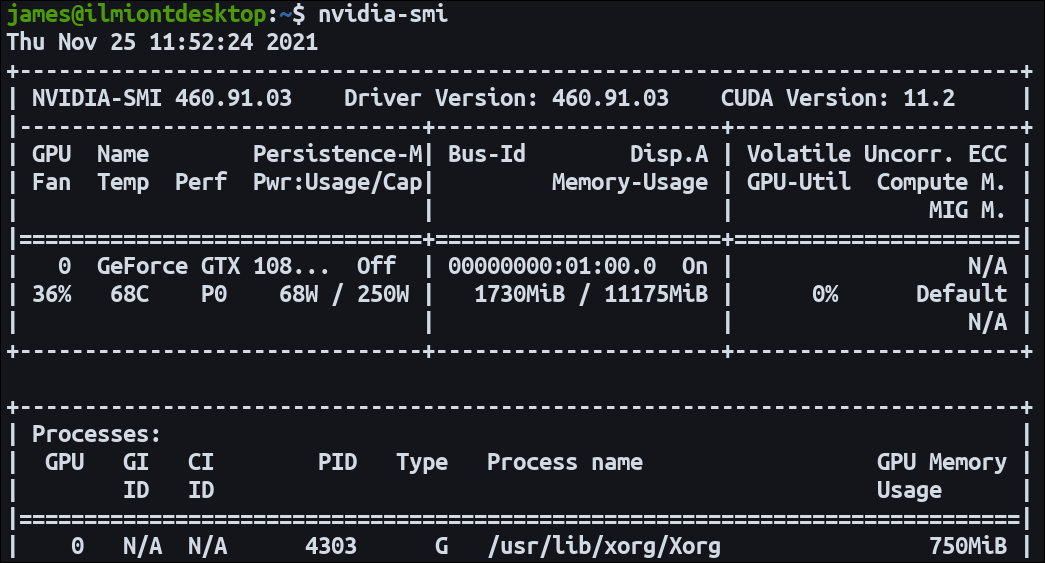
시작하기 전에 저의 nvidia-smi 값을 먼저 보고 아래 글을 천천히 읽어주시면 될 것 같습니다.
# nvidia-smi
1. NV_GPU
# NV_GPU=0,1 nvidia-docker run -it \
nvcr.io/nvidia/tensorflow:20.12-tf1-py3

제 시스템은 슈퍼마이크로 4124-TNR 모델로 A100 GPU 8ea를 사용중인데요.
그 중에 2개만 할당하기 위해서는 NV_GPU=0,1 의 옵션을 사용하여 nvcr.io/nvidia/tensorflow:20.12-tf1-py3 이미지를 사용하여 container에 진입하여 확인 하였습니다.
그렇다면 다른 옵션은 없을까요? 다른 방법으로도 GPU를 할당하여 사용하는 방법을 알려드릴께요.
2. NVIDIA_VISIBLE_DEVICES
# docker run -it --runtime=nvidia -e \
NVIDIA_VISIBLE_DEVICES=2,3 \
nvcr.io/nvidia/tensorflow:20.12-tf1-py3

runtime=nvidia를 사용하여 -e 환경변수로 NVIDIA_VISIBLE_DEVICES=2,3 GPU ID 혹은 UUID등으로 설정하여 GPU를 할당 하실 수 있습니다.
기존 NV_GPU와는 다르게 nvidia-docker로 시작하는 커맨드가 아닌 docker로 시작하는 command이니 잘 기억해 두시기 바랍니다.
또한 비교가 되기 위해서 NV_GPU 와는 다른 GPU를 사용하였는데요. 위 NV_GPU 사진에서 Bus-Id와 현재 NVIDIA_VISIBLE_DEVICES를 비교해 보시면 각각 다른 GPU를 사용한걸 아실 수 있습니다.
3. --gpus
# docker run -it --gpus '"device=0,1,2,3"' \
nvcr.io/nvidia/tensorflow:20.12-tf1-py3
다음으로는 gpus 옵션을 사용하는 것입니다.
gpus옵션을 사용하기 위해서는 위와 같이 docker run으로 시작하는데요. --gpus 뒤에 '"device="' 옵션에서는 큰 따옴표와 작은 따옴표가 반드시 필요합니다.
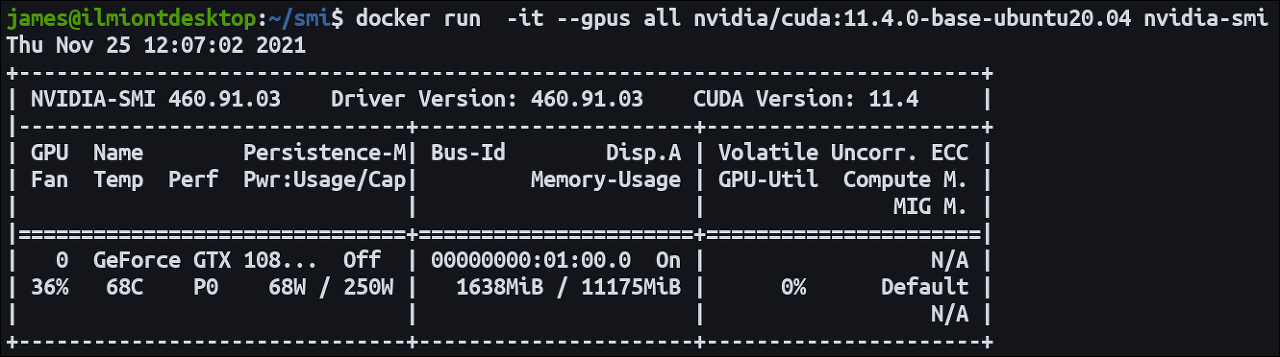
마지막으로 GPU를 한번에 다 사용하기 위해서는 --gpus all 이라는 옵션을 간단하게 사용하면 아래와 같이 모든 GPU를 할당하여 컨테이너로 진입하게 됩니다.
# docker run -it --gpus all \
nvcr.io/nvidia/tensorflow:20.12-tf1-py3

NV_GPU ? NVIDIA_VISIBLE_DEVICES? gpus?
이제 nvidia gpu 할당을 잘 하실수 있으실텐데요. NV_GPU와 NVIDIA_VISIBLE_DEVICES 및 gpus 차이점은 어떤 차이가 있는지 궁금하신 분들이 있으실텐데요.
nvidia-docker2가 설치가 되어 있는 상태에서는 어떠한 command로도 사용가능합니다.
다만 차이점은 아래와 같습니다.
NV_GPU = nvidia-docker
NVIDIA_VISIBLE_DEVICES = nvidia-docker2
gpus '"device="' = nvidia-docker2
nvidia-docker 버전의 차이기 때문에 상위버전은 하위호환되기 때문에 편하신 커맨드를 이용하셔서 docker를 사용하시면 될 것 같습니다.
해당 TEST 서버는 아래와 같습니다.
'머신러닝' 카테고리의 다른 글
| nvida gpu 분할 할당 (0) | 2022.03.18 |
|---|---|
| nvidia GPU 관련 확인 명령어 (0) | 2022.03.18 |
| 머신러닝 텍스트 데이터 변형 프로세스 (0) | 2022.03.18 |